Computers store information on hard disks and on floppy disks. The information is stored as magnetic signals. When the computer is turned on it can also store information in its RAM (Random Access Memory) which will be lost when the machine is turned off. Some programs save your work all the time, others keep your changes in RAM. If you do not save your changes then they will be lost when you turn off the power (or when the power supply stops suddenly, like when the generator runs out of fuel). So always save your work!
A problem with approaching computers when you have never used one is actually understanding what they do. Okay, so you can type your work more neatly, or organise things more clearly, but is that all? There are training courses which often cost a great deal and do not necessarily address the issues that you deal with. You can end up spending a day or a week with someone showing you how to do things that you never wanted to do and will never want to do.
Experimenting by yourself with a computer can be the most fruitful way to learn. Don't be scared, just leap in and start doing something. You can do very little damage. To be safe, work on copies of files.
There are many types of computers on the market today. They are getting cheaper, faster and able to hold increasingly larger amounts of information.
We cannot advise you on what computer equipment to buy. However hard disks should hold at least 100Mb, preferably more. We are seeing software grow in size and in RAM requirements, so also consider getting as much RAM as you can. On a Macintosh computer today you should have at least 8Mb of RAM.
Besides a computer you may want to have access to the following:
- modem, for dialing up and connecting to others (fax modems allow you to send
and receive faxes on your own computer).
- CD drive, to get ideas from the multimedia available on CD.
- scanner, for digitising pictures and illustrations.
- sound digitising equipment (like MacRecorder).
In the age of electronic data, the possibility of sharing information is becoming easier, especially through improved communication channels. We can now send electronic information around the planet using electronic mail (e-mail), or disks. You can be working on material with someone on the other side of the country, and send corrections and new work to each other instantly. The advantage of using e-mail is that you send or receive a file to work on, not paper that needs to be marked up and retyped.
There is a great deal of shareware (copies are freely available but you are asked to pay a small amount to the author) or freeware (costs nothing) which is available from local electronic bulletin boards, or, if you have access to the internet (the main electronic academic network), on many such places around the world. With access to this information source, you can send messages direct to users of the same software anywhere in the world, and ask for help from the manufacturers of the software.
A useful location on the internet to explore is sil.org, based at the main office of the Summer Institute of Linguistics, who produce some excellent software tools for language work. For Macintosh information you could also browse ftp.apple.com.
If you do not have access to the internet through a local university or college, you can buy an account on Pegasus networks which will give you access to much of the information described above. Pegasus accounts are accessed through an Austpac telephone number which is a local call cost. This is of great benefit to users outside metropolitan areas. Contact Pegasus at PO Box 284 Brisbane, Qld, 4006 (Phone 07 257 1111).
Electronic data is vulnerable to damage, especially if it is stored on floppy disks. If you put a floppy disk near a magnet it can corrupt the disk and lose all of the data held on it.
Always keep copies of your work. If it is important work then keep regular backups, and make sure they are not all kept in the same place (what if the office or house burns down!). You can deposit copies of your data with an agency that is specifically set up to keep safe copies. ASEDA will perform this function for you.
To be sure of having a recent version of your work you should backup to two sets of disks and stagger the back up over two sessions so that <disks A> get written to the first time, then <disks B>, then <disks A> again the next time. This way you will always only lose the last set of work if your computer dies while doing a backup. There is backup software available which only saves new or changed files, and also allows you to automatically backup at some particular time (at night, or at lunchtime).
Copyleft
Robin Cover, in a discussion on the electronic mailing list HUMANIST argues that, rather than entrenching ownership of information, we advocate copyleft in which: "protection is given to public property. The copyleft philosophy does not imply that the data must be made available absolutely free of charge (media costs are allowed when appropriate), but guarantees that no one can establish ownership or control over the data, that no one may commercially profit from its sale or distribution, that no one may restrict access to the data. The receipt, use, duplication, modification and further distribution are allowed ONLY on the terms that the original freedoms of the text/data/program are passed on to others, in perpetuity. This legal instrument encourages democratic access, use and enhancement of textual knowledge but prevents monopolistic entrepreneurial control by anyone."
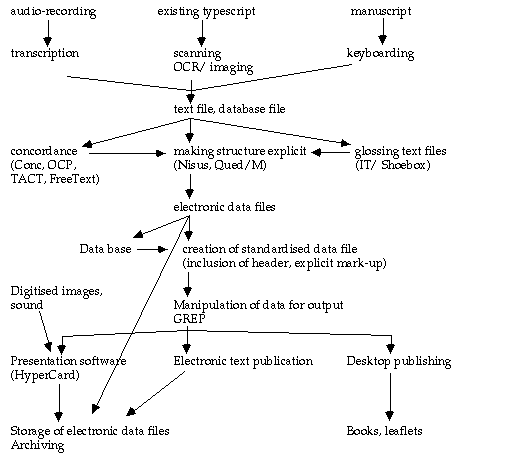
This chart shows some of the process undertaken to transcribe and manipulate texts.
When you come to type your material, or scan it from other sources, you will end up with a file created with some word-processing software. Such a file can be of greater use to you and of more use to others if you plan well before you start. Each type of word-processing software has its own way of coding the text you type in, sort of like wrapping it in different types of paper. When you read about text files in these notes they refer to the unwrapped text, the way it is when you use the 'Save as' menu (on most Macintosh software) which usually gives you the option of saving as a text only, or text with line breaks file.
Ordinary word-processors allow you to format text in all sorts of ways. You can use different typefaces, typestyles, paragraph structures, indents and so on. However, the best way to work on files that you will produce in a book sometime (perhaps a dictionary) is to keep them as free of formatting as possible. This is because you will probably change your mind about how you want the page to look a number of times before you finish.
If your text file contains a wordlist or dictionary, see the section Creating dictionaries. If you are working on translations of texts, see the section on interlinear text processing.
You should think of the structure of your file and work on maintaining a consistent structure. In a dictionary, you may have a head word, part of speech information, definition, example sentence, translation of the sentence, and so on. These are structural elements of your data. If you are aware of the structure of your data, you are better able to build a consistently formatted document.
At this point, you may want to put your data into a database programme, see the section on database programmes.
You should work with the structure of a file, declaring what the structure is so that you can later alter the data shape over the whole file (that is globally) without having to work through it manually, changing each individual word by hand. Note the difference between marking-up a file in this way and marking-up a file that you would send to a typesetter, or that you are going to produce with an outputting programme like TeX or LaTeX. The latter is called procedural mark-up, it describes procedures that the document will undergo, with commands like 'turn italics on' or 'start header layout now'. With data files of the kind we are discussing here, it is more useful to declare what structures are present in the document, leaving decisions about how they will be presented for later. Indeed, for many of the files you produce, their only form may be electronic. They may be the data files that you analyse for the production of a dictionary, or they may be a working dictionary. We suggest that you structure these files so that you can address the data in them, confident that certain structures exist throughout the files, no matter how big they become, and that automatic manipulations of text in those files can be carried out with confidence. In addition, the files can be made available to other researchers who may want to rework the data to present it in different ways.
How do you declare the structure of a file? By using a coding system within the file. Fortunately there are coding systems in use which you can follow. For dictionary creation in Australian languages, the most common coding system (or mark-up language) is the backslash code system used by the Summer Institute of Linguistics/ Wycliffe Bible Translators. This is discussed in detail in Appendix 1
Another system, now a standard used by government agencies all over the world, is standard generalised mark-up language (SGML). Ideally all texts would be marked up in an internationally recognised standard such as SGML, but most of us at the moment do not have the resources available to do this kind of work. A page of a sample document in SGML is included in Appendix 3 on page .
These mark-up languages allow files to be made available on any type of computer, from any kind of media (tape, disk or electronic mail) and to be accurately interpreted and used by other users, again, independently of the computer used.
In addition to the structural mark-up, all files should include a header, a few lines that tell the reader what is in the file, who produced it, when, and any other information that is relevant, including the type of mark-up that is used, e.g.:
\id This is a typed version of some notes that were found in the bottom drawer
of a cupboard in a house in Nuriootpa west in January 1992.
\id Codes as per standard list.
\id Note that # marks illegible text.
Spelling systems and special characters
We are fortunate that, in general, we do not need to use special alphabetic or syllabic characters to represent Australian languages. However, the orthographies of some languages do use characters beyond the 26 letters of the alphabet. In Pitjantjatjara and Yankunytjatjara, retroflex sounds are underlined (as in Kata Tjuta, the local name for the Olgas), and in languages of eastern Arnhem Land, underlining, umlaut (ä), and the phonetic character engma are also used. When creating an electronic text, it is important that these characters not be rendered using a particular font, but that they be marked in some way. Remember we are declaring their existence so that they can be represented appropriately on any computer platform. When you want to produce a prined version you can search for your coded symbol (eg, äaut) and replace it with the appropriate character (ä).
A problem that has emerged with the fonts used to write languages of Arnhem Land is that there are several different fonts in use for the small set of particular characters used in Yolngu languages. One of the fonts uses an option key combination and another uses ordinary keyboard characters. Each has its own advantages and disadvantages, but both result in files that need to be reworked to state what the fonts are meant to be. Ideally, non-standard fonts should be represented in some way that permits them to be read on any computer.
The simplest solution is to declare, at the beginning of a file, what non-standard characters appear in the file and how they are represented (eg: \id á is a acute). The international standard, using SGML is to write <á> wherever it occurs in the file. Using the font 'Geneva YM' the following characters are rendered as letters of Daatiwuy: `, [, {, ], =. In a document that includes this font, the following note should be provided together with the document, preferably as a header within the document.
underscored l - <`> (= retroflex l in Daatiwuy)
underscored d - <[> (= retroflex d in Daatiwuy)
underscored n -<]> (= retroflex n in Daatiwuy)
underscored t - <=> (= retroflex t in Daatiwuy)
When you start building your dictionary it is easy to be concerned with how it will look when you finish. However it is very important to work on the structure of your data, and to be sure you have the type of information you want in it, rather than highlighting words with bold or italic styles (for example). If you have a well defined structure in your file, it will be simple to change formatting, font style or size right through to the moment of printing. Codes in the text file can be hidden so that they will not print out. This means that your data files can also be your final camera ready work, and that any corrections you make to your work will not have to be copied back to some other data files.
Ways of constructing dictionaries
A dictionary lists words of a language with their meanings. Usually the
dictionaries written for Australian languages are bilingual, with the main word
being in the Australian language and the definition in English. A list of words
and their equivalents is the simplest type of wordlist. Dictionaries typically
include more information, including any of the following:
part of speech
definition
examples and translations
antonyms
synonyms
cross references
sources for all of the above
If you have started with a wordlist which has come from a concordance of texts (see the section below on concordancing software ) then your first file is a list of words. You will need to go through the whole list and supply meanings (or 'glosses').
If you have a wordlist which is produced from a text-glossing programme (like IT) then your first file will be a list of words and glosses, separated by a tab.
If you have started from fieldnotes then you can construct the file as you want. It is best to include as much information as possible right from the beginning. Mark data that you are not sure about so that you can take it out later. As noted above, with some software you can hide text, while keeping it in the file.
A concordance of a text is a list of words in the text, in alphabetical order, usually showing the frequency of occurence of the word and its immediate context. Concordances can be interactive, allowing the user to select words which then display their context. Concordances can also show lists of words for sections of texts which can be useful if your text is a dialogue and you want to list words used by each of the speakers separately, or if you want sentence or text numbers included in your list.
Database programmes store data in particular places which allows them to get to that data quickly, as well as allowing changes to be made to bits (usually called fields) of the data, as designed by the user (you).
Wordlists are easily stored in databases, especially if they contain only a word and a definition. Spreadsheets (usually used for accounting) can also be used for this type of list. The IAD sourcebook on Central Australian languages lists 166 words from a number of languages, all on a spreadsheet. This and other databases (like Microsoft File, Filemaker Pro) are called flat databases because they act like a card file, with searching and sorting abilities. Relational databases (like Paradox, FoxBase, Dbase or Oracle), those which link data to other data (usually an English list to numerous language lists), can be very useful for wordlists of more than one language, especially where the data can be lengthy and include more complex information, like example sentences.
If you use a database to develop a wordlist, you can export the data to a text file for printing out, and if you need to do more complicated changes to the data, like setting up a reversal (alphabetising on one of the other languages in the list, rather than on the headwords), you can use the methods described elswhere in these notes (see Appendix 1). It can be tempting to simply switch the fields in a database so that the English field comes first, but beware! this is not necessarily a reversal. If you have an entry with a definition like a type of long-bladed spear you will end up with it being alphabetised under the letter A, instead of under S for spear, or L for long-bladed.